以下文章转载自公众号“Political理论志”
编者荐语:
这篇研究展示了机器学习在衡量西方民粹主义程度上的潜力。本文通过使用基于监督机器学习的文本即数据方法,提出了一种衡量政党民粹主义水平的系统方法,作者通过对欧洲六国近 20 年268 个政党的选举宣言中提取的 243659 条句子进行了文本分析,揭示了民粹主义在各国的演变趋势。实验结果表明,各国民粹主义程度间存在显着差异。民粹主义在意大利急剧上升,而在其他国家则呈现出不均衡的趋势。这篇文章介绍的方法对民粹主义方法论提供了重要的启发,该方法还可以应用于检查更大的时间间隔、其他类型的文本来源或其他类型的政治和社会现象的演变与发展。
关于民粹主义比较研究的的一项难点是在于其涉及大量政党和国家之间以及其内部在时间和空间上的衡量。先前的研究表明,文本分析方法对于克服这一难点是有用的,机器学习方法则可以进一步改进这个方向的研究。本文提出了一种方法,使用监督机器学习方法对西方政党的选举宣言进行文本分析,从而衡量西方政党民粹主义的程度。
Jessica Di Cocco 罗马大学经济学系
Bernardo Monechi 索尼计算机科学实验室
Di Cocco, Jessica, and Bernardo Monechi. "How populist are parties? Measuring degrees of populism in party manifestos using supervised machine learning."
Political Analysis 30.3 (2022): 311-327.

本文作者 Jessica Di Cocco(左)Bernardo Monechi (右)
西方民粹主义比较研究的主要挑战之一是如何在大量案例中衡量西方民粹主义的程度。以前的文献已经使用不同的方法探索了这种可能性,其中就包括了文本分析。而机器学习的出现为这一方向的进一步研究扫清了道路,可以更快地处理数据和更准确的预测。基于自动化工具的文本即数据方法对于调查差异化的政治问题非常有用,因为它可以用更少的资源分析大量数据,直接从文本中推断参与者的立场并获得更多可复制的结果。鉴于这些特征,越来越多的比较民粹主义研究依赖于通过监督学习进行的计算机辅助文本分析。
本文
借鉴了自然语言处理中常用的技术,
提出了一种基于监督机器学习(
Supervised Machine Learning
)
的
方法来衡量西方
民粹主义
。
本文的实践
表明,使用文本数据
和机器学习可以显着改进该领域的研究并减少人工编码技术固有的局限性。
本文衡量了六个着悠久民粹主义政党传统的西欧国家(意大利、法国、西班牙、德国、奥地利和荷兰),并通过使用随机森林分类算法(
Random Forest classification algorithm
)得出反映各国民粹主义程度的分数。
本研究从这几个国家中近二十年的
268 个
政党的选举宣言中提取的
243
659
个句子进行了文本分析,研究周期是从
2002
年到
2019
年。
使用政党的选举宣言作为样本来衡量民粹主义并非没有争议。
一个主要的反对论据是,相对于其他类型的政治文本,选举宣言里的“客套话”比较多,可能难以足够反映
出政党的民粹主义立场。
然而,政党宣言普遍是以文献为基础的,并满足一些政治活动(比如竞选)的实际需求。
即使政党宣言很少被广泛阅读,它们也是官方文件,具有探索政党立场的重要价值。
此外,选举宣言也传达了特定时期的政党的立场并体现了当下政党
与选民之间的关系。
它们展示了政治行为者如何利用经济、社会和心理危机作为竞选活动的筹码,并在政党的承诺和实践之间设定界限。
另外,相比演讲等其他类型的政治文本,宣言也很容易获取。收集它们的便利性和文本的可比较性,使它们适合进行旨在获得政党立场的精确时间线的比较分析,这对各党派民粹主义水平进行一致、有效和可靠的时间和空间比较的提供了合适的样本。
如何定义民粹主义一直是多项研究工作的核心。该术语的不明确性质导致书籍、论文和文章中出现了大量的定义。虽然其中一些以强有力的领导或自上而下的动员等组织特征为中心,但另一些则强调经济方面的中心地位。定义民粹主义的一种常见方法是“理想方法”。它将民粹主义视为一系列思想,将政治理解为具体化的人民意志与阴谋精英之间的斗争。这种思想通常将人民描述为同质和善良的,并将精英描述为自私和腐败的。民粹主义思想的简单性使其能够适应不同的环境。因此,民粹主义的几种变种是基于每个社会中民粹主义力量政治化的最相关的社会不满而发展起来的。
本文认为,民粹主义是通过政治文本所表达的一系列思想,它崇尚人民主权,并将政治领域理解为人民与精英之间的斗争。这一定义基于这样的假设:政党的民粹主义及其水平可以通过政治语料库的文本分析来评估,并且不一定是稳定的。在不同的时间和空间环境中,民粹主义主张的存在可能存在很大差异。这意味着随着时间的推移,政治参与者可能并不总是表现出相同程度的民粹主义。
通过文本分析方法衡量民粹主义
使用文本分析来衡量民粹主义的原因有两个。首先,它允许关注精英及其想法,其次,它允许在国家内部和国家之间的大量案例中衡量民粹主义。
然而,迄今为止提出的一些文本分析方法论仍存在结构性的局限,特别是当它们严重依赖人工注释过程来分析庞大的语料库时。减少与个体评估相关的主观偏见并确保编码人员间的可靠性需要参与资源密集型编码程序的众多编码员的参与。
此外,本研究的比较分析涉
及多语言的数据集,如此广泛的语料库的编码
很难仅由一两个研究人员完成。
自动文本方法的
出现可能有助于克服其中一些限制,例如允许在短时间内用有限的资源分析大量文本。
Hawkins 和 Castanho Silva 的一项研究展示了使用自动文本分析来衡量民粹主义的潜力(Hawkins
et
al,
2018)。
他们使用机器学习技术对 154 个文档进行监督分类
由使用整体评分(H
olistic Grading
)训练算法的演讲和宣言组成。
整体评分是一种以人为本的方法,旨在从整体上评估文本,
用于分析文本的统计模型基于词频比较;
它对预测文档是否应归类为民粹主义的词语进行加权。
在将结果与通过人类编码获得的结果进行比较后,他们得出结论,只要有足够大的数据来训练模型,计算文本分
析就
有可能识别出民粹主义。
三、研究数据
本
研究的数据集包括来自 99 个政党的 268 份选举宣言,总共 243659 句话。
本研究从宣言项目数据库(
Manifesto Project Database
,MPD)(Krause et al, 2018)下载了 229 份宣言,并将该数据库与从政党和政府官方来源获取的 39 份额外宣言进行整合,以便更准确地反映各轮选举中的政党格局。由于数据可用性不均且难以将其与新宣言整合,尽管确保至少三轮选举以改善时间比较,但并非所有国家都有相同数量的选举轮次。例如,意大利的宣言涵盖了 2006 年至 2018 年,荷兰宣言的时间跨度是 2002 年至 2017 年,西班牙的宣言则是 2004 年至 2019 年。
鉴于民粹主义在不同类型的文本中也可能有所不同,建立一个包含领导人演讲的替代语料库将是本研究领域的一项进步。这种文本的特殊性,是衡量民粹主义的文本方法的一个重大弱点,演讲和宣言之间的交叉比较可以对解决这个问题产生提供帮助。因此,本研究还有一个额外的语料库。以意大利为例,本研究
还有一个包含 2151 条句子的语料库,这些句子取自 2006 年至 2019 年意大利政客在竞选活动、脱口秀和电视节目中的演讲。本文将
使用该演讲语料库将该方法与使用不同方法的方法进行了比较。
数据处理
我们按照自动文本分析中的标准程序准备了数据集。我们根据选举程序的结构和语言将每个国家语料库分成句子。句子经过预处理,将所有单词转为小写,并删除标点符号、数字和连词词(例如,and、but 和 or)。然后将每个句子转换成一个“词袋”(
bag-of-words
)
。
词袋是一个矢量 X = [X1 .
. . XN ] 分配给每个句子,其中 N 是所选国家/地区清单中的单词总数。
每个元素 Xi 对应一个特定单词,如果单词出现在句子中则 Xi =1,否则 Xi =0。
我们使用词袋矢量作为随机森林的输入特征来区分分配给每个句子的标签。
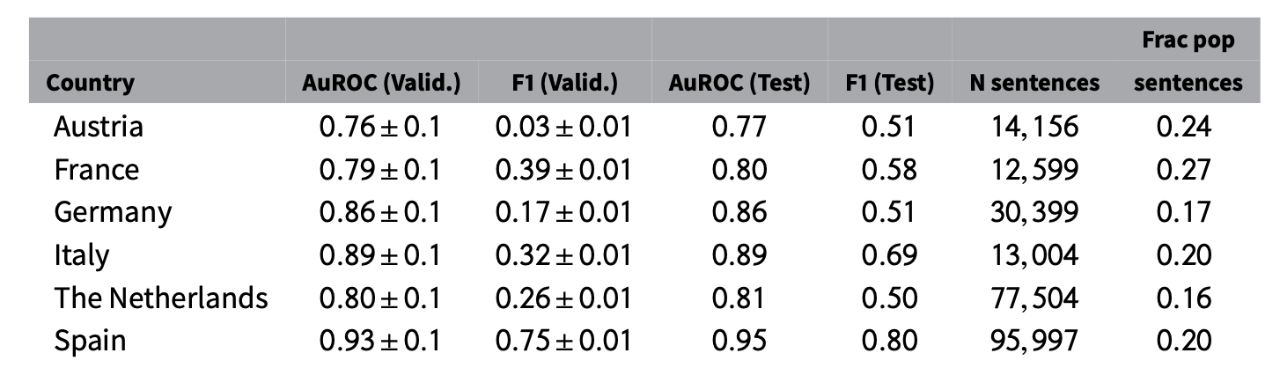
图 1:关用于验证和测试的操作特征 (AuROC) 水平和 F1 分数的领域的详细信息,以及每个国家属于民粹主义宣言的句子数量和句子比例。
随后,我们以
https://populist.org/
为参考依据,将标签 Y =1 分配给该网站中分类为民粹主义的政党,比如意大利的人民力量党(PaP),这是一个新兴极左政党。同时,我们为属于不被视为民粹主义的政党宣言的所有句子赋予标签 Y = 0,例如意大利民主党 (PD)、法国共和党 (LR)、西班牙人民党 (PP)、德国基督教民主党联盟 (CDU)、奥地利社会民主党 (SPÖ) 和荷兰自由民主人民党 (VVD)。在此阶段,我们从数据中排除了那些随着时间的推移民粹主义模糊或仅在某些分类中被视为民粹主义的政党的宣言,例如前进意大利党(FI)、新反资本主义党(NPA)等。图 1显示了属于民粹主义政党的宣言(即标记为 Y = 1)的句子的比例。
最后,我们将每个国家数据集分为两部分,一部分用于训练和验证,另一部分用于测试。
对于每个国家,70% 的句子用于训练和验证,让模型学习如何进行预测并使用 k-Fold 交叉验证调整其超参数,其余 30% 用于测试其预测能力 样本数据并建立分数。
对于最终分数的推导,本文采用
随机森林算法
,该算法能够区分属于特定国家的民粹主义或非民粹主义政党宣言的句子。 最终的政党得分被认为属于其国家典型民粹主义政党宣言的宣言句子的一部分。
该算法的优点是确保在非线性关系的情况下进行准确预测
。
这一特性支持其在许多主题中进行预测,包括投票行为、党派偏见和政治情绪。
在缺乏单语种语料库的情况下,我们对每个国家的语料库进行了单独的训练,获得了六种不同的模型。利用带标签的文本数据,我们构建了能够为每个文本块分配相应标签的模型。随后,我们用随机森林算法的一组超参数进行推导,以根据分类精度指标找到六种模型间的最佳组合。
我们使用 k-Fold (交叉验证法)估计了每种超参数组合的分类准确性。训练集最初分为 k = 5 个子集。因此,k − 1 个子集用于训练模型,而剩余的一个子集用作验证集来计算准确性。对于 k − 1 子集的每个可能选择,重复此过程,每次都重新训练模型。分配给超参数组合的准确度分数是通过重新训练获得的所有分数的平均值。由于准确度分数有多种可能的选择,我们使用了AuROC 曲线下的面积,因为它通常在二元分类任务中是首选。
五、实证结果
模型的测试和分值的建立
在构建分数之前,我们使用为每个国家找到的最佳参数集测试了随机森林的准确性。因此,我们使用六个特定国家的模型对测试集中的所有句子进行分类,并计算相应的 AuROC (接收者操作特征曲线,即本测试的评价指标,编者注)。为了完整起见,我们还计算了验证集和测试集的 F1 分数 (精确度)。
上文图 1 显示了测试集和验证集的 AuROC 和 F1 分数。虽然测试集的 AuROC 与相应的平均验证分数相差不远,但测试集的 F1 分数通常高于验证集的 F1 分数。
图 2 则展示了基于民粹主义相对分数的一个样本示例,并显示了使用民粹主义得分进行比较分析的潜力。根据这个衡量标准,通常不属于民粹主义者的政党也可能表现出一定程度的民粹主义。
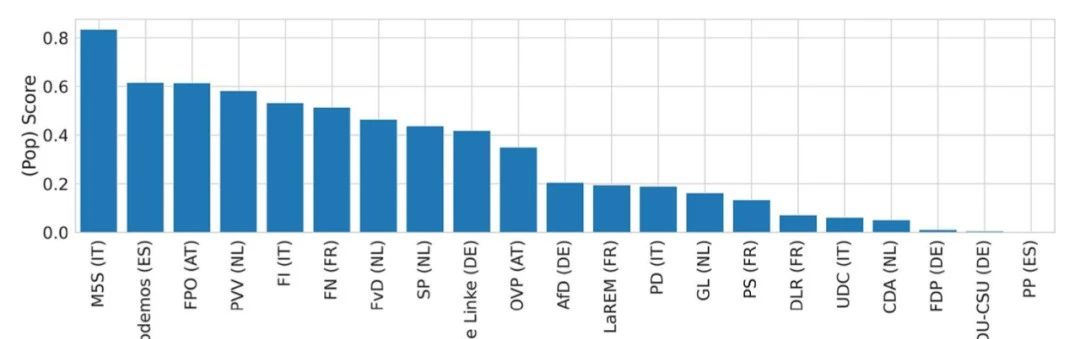
图 2:如何根据相对分数对各方进行排名的示例。这些分数是通过为每个国家训练一个模型而得出的,并参考各国最近一次的全国选举。
数据验证
为了验证本实证研究中得出的结果,我们
依赖于先前相关研究中得出的民粹主义相关维度。即 CHES和 POPPA 以及 GPD 数据库中的相关评分。
首先,本研究借鉴了
数据库 CHES (
Polk et al, 2017),并选择其中的“反精英显著性”(anti-elite salience
)和“人民与精英”(
people vs elite
) 为比较维度。反精英主义通常用于挑战者政党的叙述中,可以被定义为对精英的明确攻击。 “人民与精英”维度,根据 CHES 数据库所述,它反映的是直接民主与代议制民主的立场的衡量。
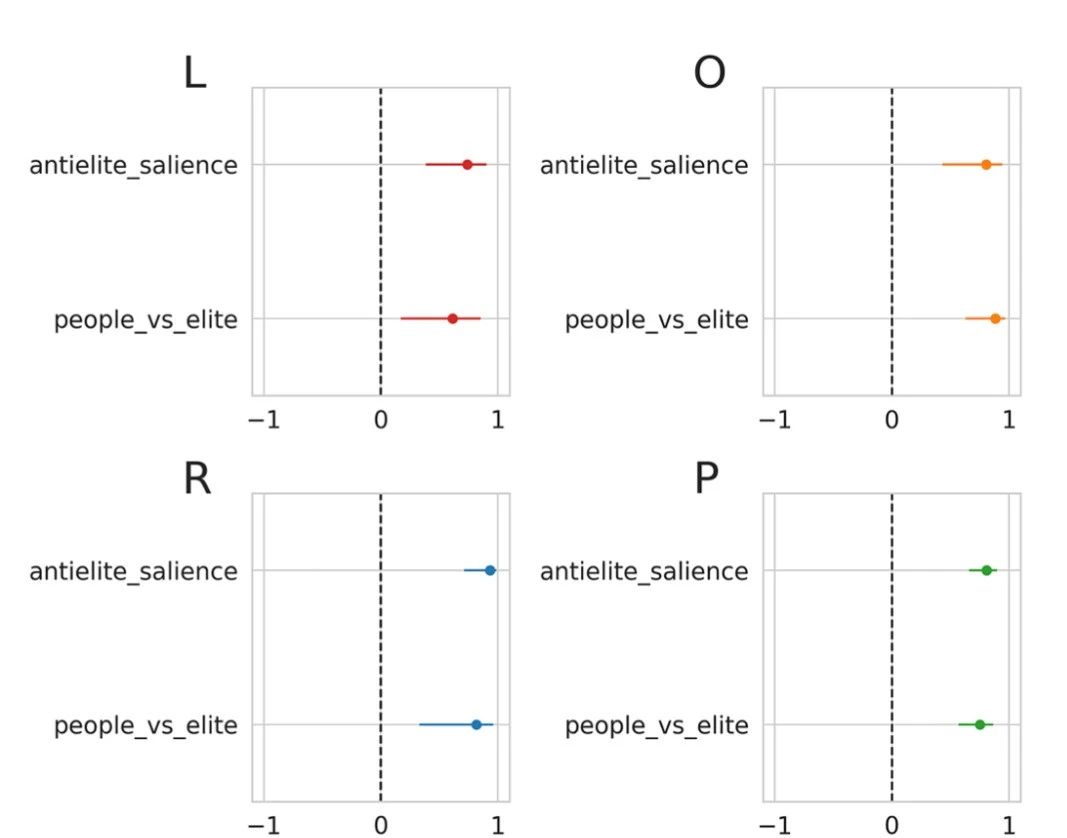
图 3:左翼 (L)、中间派/其他政党 (O)、右翼 (R) 和所有政党 (P) 的民粹主义得分与 CHES 相关维度之间的相关性。水平线代表相关系数的 95% 置信区间。
其次, 我们借鉴了POPPA 数据库(Meijers and Zaslove, 2020)中
关于民粹主义的五个属性。
POPPA 数据库对对28个欧洲国家的250个政党的立场和态度进行了排名,排名维度涉及与民粹主义、政治风格、政党意识形态和政党组织相关的关键属性。POPPA 数据库 并不是强加民粹主义的具体定义,而是旨在衡量每个政党体系中所有政党民粹主义主导概念背后的相关构成维度。 与 CHES 数据库不同的是,POPPA 数据库更明确地关注民粹主义属性。
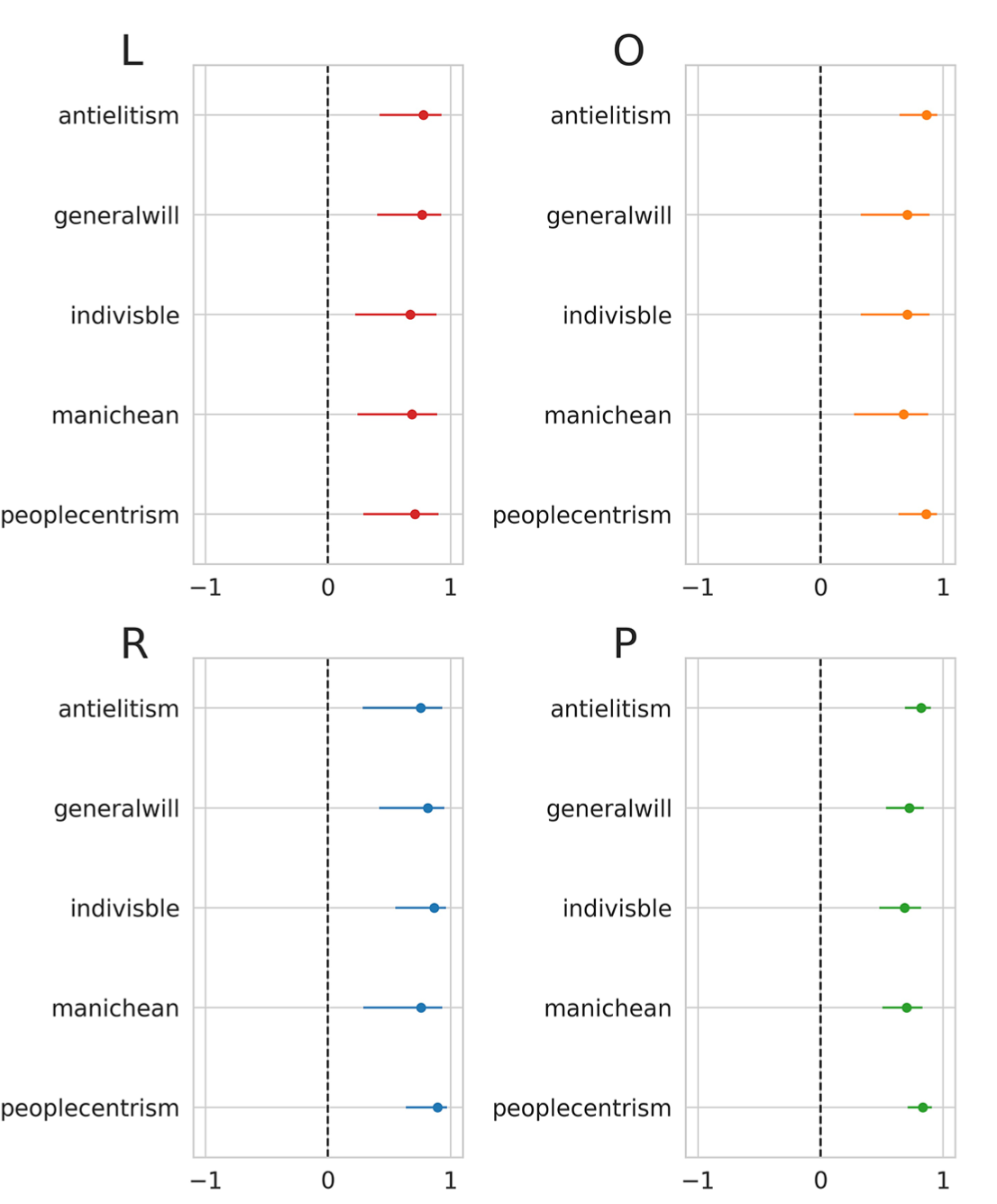
图 4:左翼 (L)、中间派/其他政党 (O)、右翼 (R) 和所有政党 (P) 的民粹主义得分与 POPPA 相关维度之间的相关性。
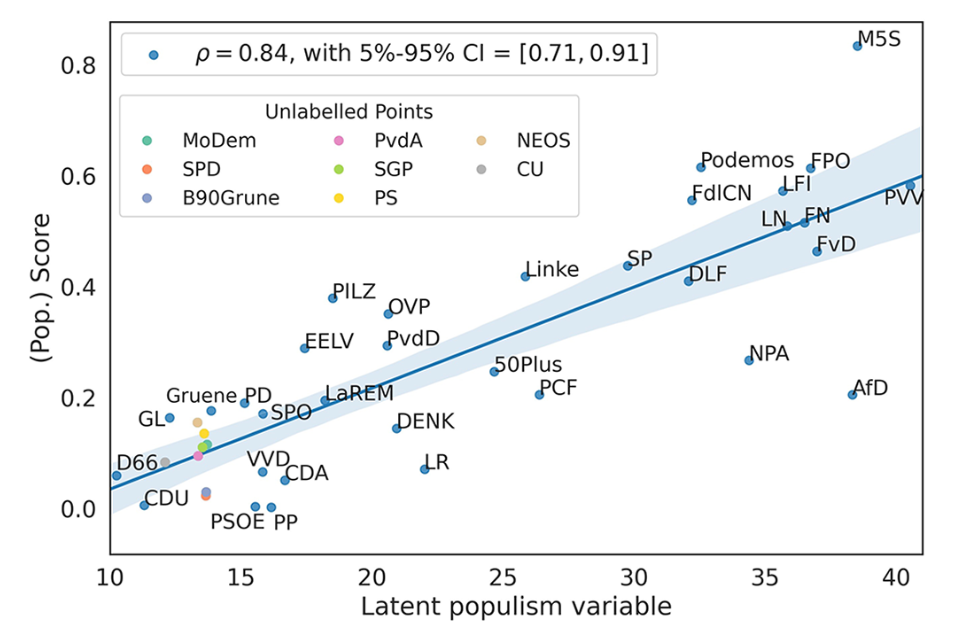
图 5:政党的民粹主义分数与 POPPA 中的五个民粹主义变量之间的相关性
GPD 数据库(
Hawkins
et
al,2019
)则衡量了全球66个国家的215位政治领导人(总统和总理)演讲中的民粹主义话语水平。该数据集包含 1000 多个演讲,大部分发生在 2000 年至 2018 年之间。每个演讲均由一两个编码员使用上文提到的整体评分技术进行手动编码。使用多个验证源使我们能够评估结果的有效性并提供对分数捕获的维度的见解。
结论 1:随时间演变的民粹程度
通过衡量政党民粹主义每年的平均总体水平,我们可以得出不同国家民粹程度随时间的变化。这一指标将在全国选举中获选率低于 1% 的政党排除在分析之外。
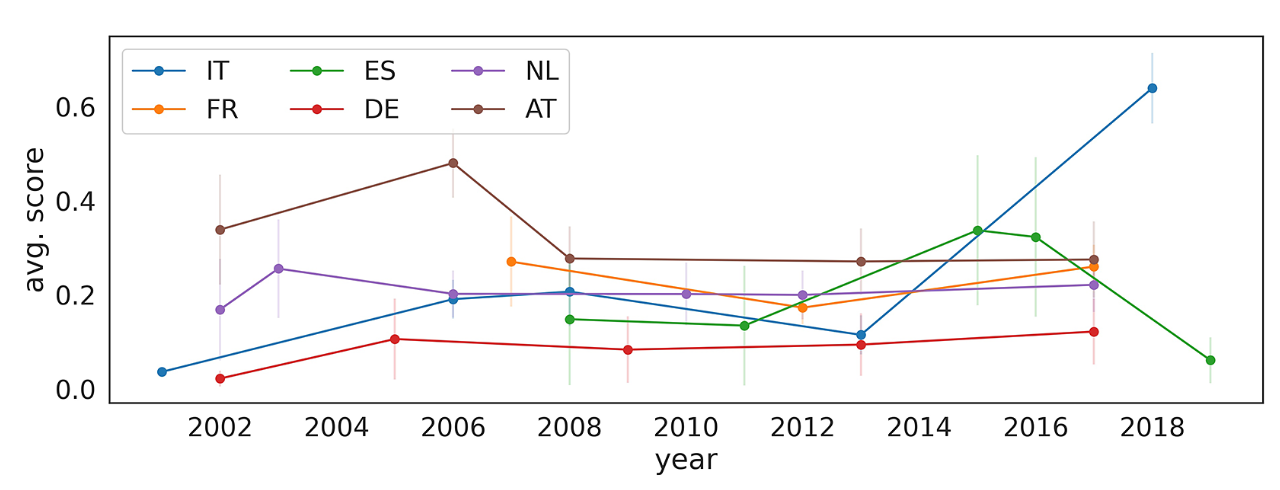
图 6:各国民粹主义平均分数的趋势
图 6 显示了我们数据中所有研究的国家在不同年份的平均得分。尽管各国的趋势存在差异,但结果显示,意大利的民粹主义平均得分急剧上升,而其他国家则表现出增长较弱或趋势不均匀。西班牙民粹主义的平均水平显著下降。我们的研究结果表明,对民粹主义决定因素的研究应该
不仅局限于 2008年的经济危机,并探索其他转折点(例如难民危机或身份认同危机),这些事件都有可能推动一些国家平均民粹主义上升的可能 。
结论 2:随时间演变的民粹程度
此外,本研究认为研究民粹主义政党成为执政党前后的变化也是非常重要的。
图7 显示了一部分政党的民粹主义分数随时间的演变,包括奥地利人民党 (ÖVP)、荷兰绿色左翼党 (GL )、德国左翼党 (Die Linke) 和西班牙人民党 (PP)。
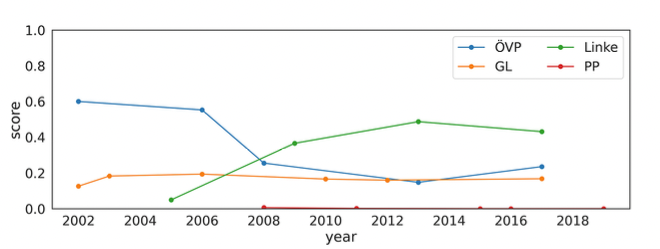
图 7:奥地利人民党、荷兰绿色左翼党、德国左翼党左派和西班牙人民党的民粹主义分数随时间的演变。
GL 和 PP 的民粹主义水平只有很小的波动,而 Linke 和 ÖVP 随着时间的推移却呈现出多样化的轨迹,前者的特点是民粹主义水平急剧上升,后者的特点是民粹主义水平下降。 值得注意的是,本研究涵盖了每个国家至少三轮选举周期中出现的所有政党的演变。
六、讨论
近年来,研究民粹主义的方法论有所发展,它试图系统地和比较地衡量政党民粹主义。
本文通过使用基于监督机器学习的文本即数据方法,提出了一种衡量政党民粹主义水平的系统方法,从而丰富了现有文献。
与基于计算机辅助文本分析的其他方法不同,我们提出的方法是基于对文本单元的观察,而不是对整个文本的观察。
此外,它衡量的是政党而非领导人的民粹主义水平;
并且不依赖于人工编码
。
它具有四个主要优点。
首先,它通过识别大量政党的民粹主义水平来对大量政党进行分类,而无需资源密集型的人工编码过程。
其次,它获得政党得分来对民粹主义进行时空分析,这一特征可以导致比较研究的重大进展。
第三,它提供了衡量政党民粹主义的持续分数。
持续的相关实践有助于分辨政党展现的民粹主义是真民粹主义还是战略上的技巧,为对民粹主义的相关因素进行更细粒度的分析扫清道路,并降低任意分类的风险。
第四,与其他衡量民粹主义的方法不同,它以较少的时间和资源分配获得更新且快速的结果。
此外,即使研究人员很少或根本没有多语言知识,我们的方法也可以进行文本分析,这从空间比较的角度来看是至关重要的。
本研究
通
过对意大利、法国、西班牙、奥地利、德国和荷兰六国从
2000
年代初近二十年的民粹主义进行空间和时间比较分析,展示各国民粹主义程度间存在显著差异。
民粹主义在意
大利急剧上升,而在其他国家则呈现出不均衡的趋势。
最后,我们对这个民粹主义衡量指标的首次应用强调了探索持续措施相对未开发的潜力的重要性,以调查广泛的民粹主义相关问题,例如民粹主义时代精神,民粹主义的不同属性的演变,或者民粹主义与经济(或社会/政治)危机之间的关系。
该方法还可用于检查更大的时间间隔、其他类型的文本来源或其他类型的政治和社会现象。

 最新公告
最新公告