中国人民大学数字人文研究中心“星火训练营”旨在为学生研究员提供更为系统的数字人文学习指导和训练,借鉴国际上各数字人文中心普遍采用的“理论+方法+项目”的培养方式,立足RUC-DHC“数字人文新青年”的既有基础,邀请跨专业导师进行学术引领和指导,以参与实践项目推动数字人文理论学习与理解。
中国人民大学数字人文研究中心学生研究员“星火训练营”专题讲座010以“馆藏文物基础数据现状、知识图谱建设与未来发展”为主题,由故宫博物院数字与信息部大数据管理组叶祎珮副研究馆员主讲。讲座由中国人民大学信息资源管理学院讲师、
师资博士后
祁天娇博士主持。
叶祎珮,故宫博物院数字与信息部大数据管理组,副研究馆员。从事馆藏文物信息组织与管理、知识服务、本体构建与知识图谱建设等工作。其工作经历主要为:2012进入故宫博物院负责网站英文编辑,2013年负责APP数字展示,2015年负责数字展馆数字展示,2020年负责知识图谱和数据管理工作。
讲座主要由以下四个部分组成:
故宫博物院馆藏文物数据化、本体构建过程的经验探讨
从CIDOCCRM到CRM-ACA的本地化过程
叙词表的建设过程
故宫文物本体后续未来发展趋势和畅想
讲座伊始,叶祎珮副研究员在系统介绍故宫“三位一体”博物馆、数字与信息部(Digital & Information Department)的基础上,对自己所在的大数据管理组(2020年3月成立)的由来和具体分工进行了详细介绍。其中“三位一体”指故宫博物院是集世界遗产地、博物馆、旅游目的地于一体的文化机构。故宫大数据管理组的研究对象含
不可移动文物
(世界文化的监测数据)、可移动文物(馆藏文物的知识图谱)和观众服务(票务数据和线上产品观众访问量数据)三方面。
故宫博物院文物数据主要经历以下几个阶段:(1)1999年前,文物数据的编目信息以纸质为主。(2)1999-2019年,故宫博物院文物管理信息系统开发完成并投入使用。(3)2019年发布数字文物库线上平台,包括文物名称、文物编号、
文物分类
、文物年代四个元数据信息。
此外,叶祎珮简要介绍2017年“养心殿主题数字展”中基于FAQ问答系统的“端门数字馆‘召见大臣’交互节目”,分析了项目实施时遇到的问题,并介绍了一系列解决方案,例如知识库、知识图谱等。
2020年3月,故宫博物院引进新的团队,重新审视知识图谱项目。将项目定位、需求阐述、技术路径、产出成果、成果落地应用等环节思考清楚后,决定采用本体和知识图谱将专家研究结果变成清晰可读的数据,并将其进行数据关联。本体是表达规范的一种语言,本体表达的知识具有机器可读性,可以极大程度辅助数据推理和决策工作。在本体工程学上,复用本体可以提高数据集被其他应用程序引用的几率来促进数据关联共享。
二、从CIDOCCRM到CRM-ACA的本地化过程这是一个简单的圆形标题
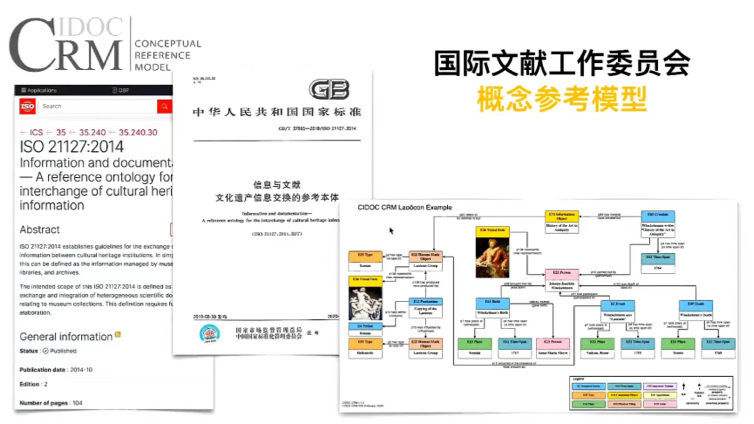
故宫团队选取的复用本体是国际文献工作委员委员会的概念参考模型(CIDOCCRM)。该模型可以说是文化遗产领域认可度最高的一款本体模型,其目标就是为了帮助博物馆、档案馆、图书馆等,将大量分散不兼容的文化遗产信息基于共同的概念基础进行比较和映射,进而实现不同信息源的信息交换和集成,从而推动文化遗产信息的共享。
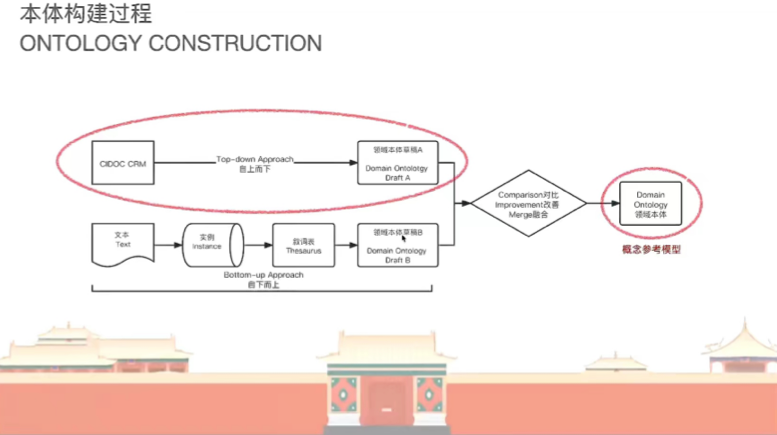
为实现细颗粒度数据的语义互操作,也为更加贴合中国古代可移动文物的信息特征,故宫团队在CRM base的基础上做扩展,让其更容易用于中国古代可移动文物的信息组。所构建的这款本体称为“中国古代可移动文物概念参考模型(CRM-ACA)”,构造方法采用斯坦福七步法。
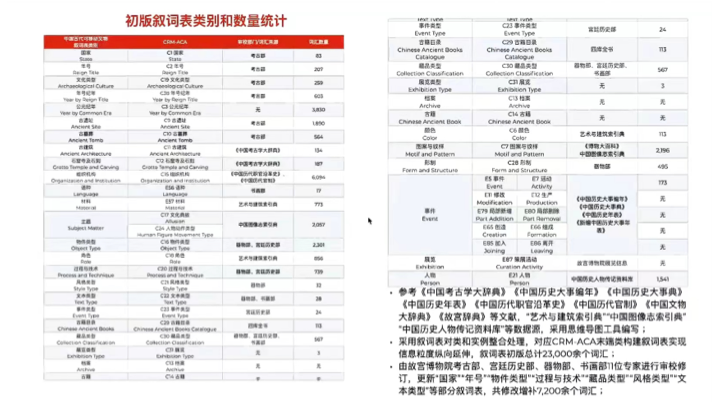
截止到2022年3月,故宫团队制作完成30个叙词表,累积词汇达23000多个,其中修改增补约7200多个词汇。
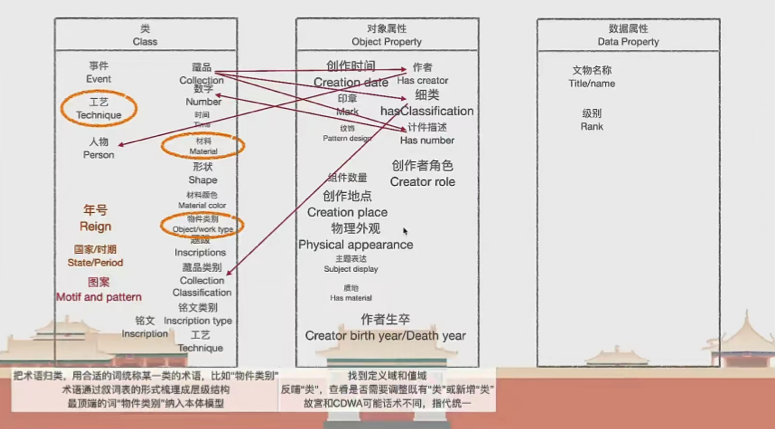
为了尽量保持本体模型的可扩展性和兼容性,仅选取词表中比较高层、抽象的术语纳入到这个本体模型,每个词表最顶端最头部的术语作为本体的类,而下面细分的细颗粒度术语,作为一个类里面的实例,从而保证这个模型层各个语义关系在一个比较宽泛的应用范围。其中对象属性(Obeject Property)即类跟类之间的语义关系,数据属性(Data Property)即给类设置原数据字段。
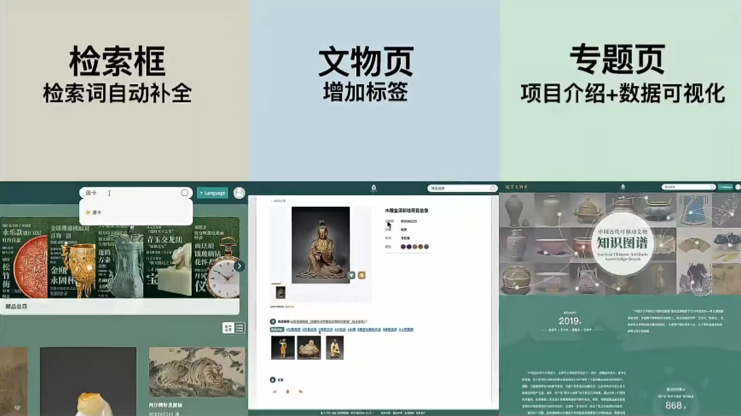
2020年10月完成本体模型1.0版本,现已经更新到1.10版本。截至2022年10月,已完成7000多件藏品标注数据并将其纳入到知识图谱数据库。今年(2023)年初知识图谱数据库已经对接数字文物库,开始正式对它提供数据服务。从数字文库前端可见来看,可以看到三个部分功能已经上线,分别是检索框的检索词自动补全功能,文物详情页的增加标签功能(可以看到藏品信息标注,并且这些标签可以点击发起二次检索),课题项目专题页(项目介绍与知识图谱数据可视化)。
目前知识图谱技术应用在文化遗产领域的案例有很多,叶祎珮副研究员对于一个博物馆数据团队在知识图谱技术应用中应该扮演一个什么角色展开了分享。
目前广泛认为
语义网络
知识图谱推动了数字人文研究,叶祎珮副研究员认为从事数字人文研究的仍然应该是领域专家和人文学者,而博物馆数据团队更多的是基于博物馆领域研究的需求和数据情况的认知,去为他们提供数据。CRM-ACA在设计过程中尽量保持了普适性,其目的就在于通过标准化向构建一个工程级的数字人文数据基础设施行进。
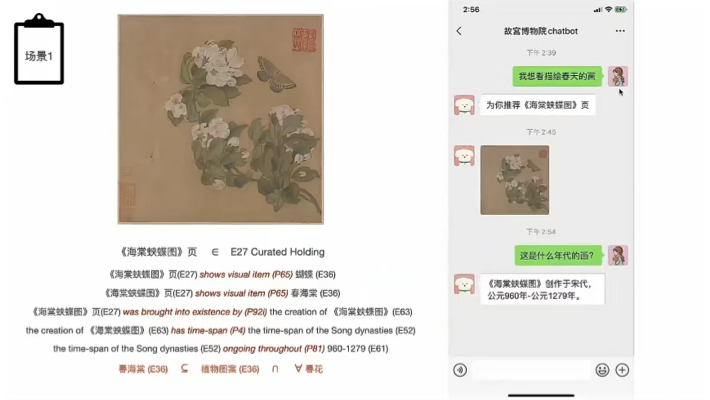
项目一期已经结束,马上就要开启二期建设,其中二期要更加充分利用本体里丰富的语义关系,推动基础数据建设、深化发展细颗粒度的数据,丰富数据之间的语义关系。增加藏品信息标注数量、升级检索功能支持多语言检索、增加语义检索功能识别用户检索意图,从而实现自然语言的检索。老师向我们分享了她的个人畅想。比如借助Chat GPT大模型,加上已做的事实性数据,做出故宫博物馆chatbot。
此外还可以实现跨机构的藏品数据整合,实现多家机构的藏品联合检索,在都采用CIDOCCRM本体框架的情况下,实现跨机构联合检索在技术上会更容易实现。
还有探索链接开放数据的形式,或许可以把知识图谱的图结构数据转化成国际标准的数据格式,然后发布成链接开放数据集。假如将CRM-ACA本体包括与其配套的叙词表发布出来,数据发布形式采用API接口,许多有技术能力的机构也可以共享调用数据。
讲座的最后,叶祎珮副研究员以《数字人文导读》里的一段话作为分享的结束语。
在热烈的问答中,本次讲座圆满结束。重温完整精彩内容,可点击下方链接获取视频回放。
中国人民大学数字人文研究中心“星火训练营”旨在为学生研究员提供更为系统的数字人文学习指导和训练,借鉴国际上各数字人文中心普遍采用的“理论+方法+项目”的培养方式,立足RUC-DHC“数字人文新青年”的既有基础,邀请跨专业导师进行学术引领和指导,以参与实践项目推动数字人文理论学习与理解。








 最新公告
最新公告