
历史报纸研究的综合性跨学科工作流程:基于人文学者、计算机科学家和图书馆员的视角
转载请注明:"刊载于《数字人文研究》2022 第3期";参考文献格式:莎拉· 奥比奇勒,伊曼纽拉· 博罗斯,安托万· 杜塞特,等. 张晨文 译.历史报纸研究的综合性跨学科工作流程———基于人文学者、计算机科学家和图书馆员的视角[J]. 张晨文,译. 数字人文研究, 2022, 2(3): 83-100.全文PDF已在知网、万方及编辑部网站(http://dhr.ruc.edu.cn)上发表,此处注释及参考文献从略。
历史报纸研究的综合性跨学科工作流程:基于人文学者、计算机科学家和图书馆员的视角
摘 要 :文章思考了数字化历史报纸等数字文化遗产研究工作在跨学科合作中的机遇和挑战,并提出了一个综合的“数字解释学”工作流程,以整合计算机科学、人文学科和图书馆工作的学科研究路径。上述学科的共同兴趣和动机促成了跨学科项目和合作,如NewsEye——该项目正在研究对数字遗产数据进行(再)检索、访问、利用和分析的新方案。文章认为,充分理解每个相关学科的工作流程和传统有益于学科间的合作,但必须找到综合性路径,以成功挖掘数字化资源的全部潜力。文章进一步对实践中的数字工具、方法和解释学进行深入观察,表明了综合的跨学科研究需要在学科之间构建起纽带,同时要尊重和理解彼此的专业知识和期望。
关键词: 数字人文;历史报纸;跨学科;数字解释学
作者简介:莎拉·奥比奇勒(Sarah Oberbichler,通讯作者),奥地利因斯布鲁克大学当代史研究所,Email:sarah.oberbichler@uibk.ac.at;伊曼纽拉·博罗斯(Emanuela Boros), 法国拉罗谢尔大学计算机图像与交互实验室;安托万·杜塞特(Antoine Doucet),法国拉罗谢尔大学计算机图像与交互实验室;亚尼·马尔亚宁(Jani Marjanen),芬兰赫尔辛基大学数字人文系;伊娃·范策尔特(Eva Pfanzelter),奥地利因斯布鲁克大学当代史研究所;尤哈·罗提亚宁(Juha Rautiainen),芬兰国家图书馆;汉努·托沃宁(Hannu Toivonen),芬兰赫尔辛基大学计算机科学系;米科·托洛宁(Mikko Tolonen),芬兰赫尔辛基大学数字人文系;张晨文(译者),中国人民大学档案学博士研究生,Email:chenwen0526@ruc.edu.cn
1 概述
”
持续数十年的数字化进程,使得历史报纸的获取对公众而言前所未有地容易。早在20世纪90年代,欧洲的各地方和国家图书馆就已经在报纸数字化方面投入了大量资金(Terras, 2011),其馆藏报纸的17%在2012年完成了数字化(Gooding, 2018)。随着欧洲数字图书馆(Europeana)报纸专题数据集的创建,一个泛欧洲(pan-European)报纸门户网站建立起来,1800万个报纸页面可访问,其中1000万页被转换为全文本。随着数字化进程的持续,自然语言处理(NLP)领域日益先进的技术有望优化史学家对全文本档案的访问。为了实现这一目标,跨学科的(interdisciplinary)研究路径应该取代在这当中图书馆、人文学科和计算机科学分立的学科研究路径。
对于图书馆来说,这些发展是实现其核心使命的一个重要优势:保存原件、提供访问服务,并致力于实现用户、信息和知识之间最大可能的互动(Van den Bosch et al., 2009; Zhang et al., 2015)。得益于数字化,图书馆可以接触到潜在的国际化和多样化的读者(Nauta et al., 2017; Neudecker & Antonacopoulos, 2016)。与此同时,图书馆的数字化尝试也使人文学者受益。在此之前,从事报纸研究让人望而生畏,材料数量之巨似乎是无法克服的问题,耗费大量时间寻找信息往往劳而无获(Abel, 2013)。
随着数字化的推进,及更精细的算法、工具和方法被计算机科学家开发出来,数字方法已经开始影响人文学科,尤其是历史学研究——其目标是通过对第一手材料如报纸文章进行探索、分析、解释和语境化来研究过去(Korkeamäki & Kumpulainen, 2019; Oberbichler et al., 2020)。一些历史学者需要创建数据集以用于进一步的定性分析(e.g., Gabrielatos, 2007),或使用数字工具来支持其定性研究(e.g., Brait, 2020; Oberbichler, 2020a; Pfanzelter, 2020);一些历史学者使用文本挖掘方法来识别语言模式(Marjanen, Kurunmäki, et al., 2020),还有一些则重新研究地理分布现象(Borruso, 2008)。
米利根(Milligan, 2019)表示,为了使用数字化的第一手材料,历史学者需要掌握新技能,尤其是在对大型的数字化的原始资料或原生数据资源进行解释和理解的(数字)解释学实践中。菲克斯(Fickers)和范德海登(van der Heijden,2020)将数字解释学(digital hermeneutics)定义为“批判地、自我反思地使用数字工具和技术,以发现新的研究问题、测试分析假设和产生复杂的科学解释”。根据菲克斯(2020)的观点,数字解释学结合了对历史实践的批判性反思及“数字素养”意义上的实践“技能”训练。此外,作为数字解释学的一部分,数字源批判解决了“由不断变化的存储逻辑、检索带来的新启发以及分析和解释数字化数据的方法所引起的”档案学和史学问题。这意味着,从“原始资料”到“文件”再到“数据”的转变,其认识论含义也需要被质疑(Fickers, 2020)。因此,数字解释学包含两个方面。一方面,它是关于如何理解作为数字化对象的数据原始资料的。另一方面,它是关于使用数字方法来处理、分析和解释这些数据的(Tolonen & Lahti, 2018)。虽然这两方面不能完全分开,但这里我们主要关注后者。
历史学者的工作中对数字工具和方法的需求日益增长,使历史报纸也成为计算机科学家感兴趣的研究领域。它为应用NLP方法提供了机会,并带来了新的挑战和问题。其中之一,即是对非常嘈杂的文本集合进行分析,这是光学字符识别(OCR)的输出和布局/分割过程产生的不完美导致的(Boros,Hamdi, et al., 2020; Huynh et al., 2020; Nguyen, Jatowt, et al., 2020)。计算机科学家还可以解决分析语言随时间变化和产生变体这一复杂问题,或帮助对涉及同一主题的文章进行分组,以支持从不同角度进行解释和事件提取(Zosa, Hengchen, et al., 2020)。计算机科学家在历史报纸研究中的任务,是识别和确定由历史研究实践所激发或从数字报纸语料库所提供的机会中产生的计算问题,并提出解决方案(算法、计算模型、软件工具等),以同时促进对计算问题和历史研究问题的理解。
基于这些不同的需求、动机和兴趣,越来越多的数字报纸研究项目将数字管护者(curator)、地理学家、计算机科学家和人文研究者吸纳进来(如,NewsEye, ViralTexts, Oceanic Exchanges, impresso, Arkindex, and Living with Machines)。这些项目正朝着协作和整合的方向努力,以更接近在数字化历史报纸数据中“发现意义”的共同愿景。《数字化报纸地图集》(The Atlas of Digitized Newspapers)是一本开放获取指南(Beals & Bell, 2020),由六个欧洲国家最重要的计算机科学期刊研究人员编写,已经朝着促进跨学科研究人员对数字化报纸有更多历史理解迈出了重要一步。
综合性跨学科研究(integrated interdisciplinary research)尝试在学科之间建立起纽带,使它们之间可以分享更多,而不仅仅是某个问题。这与多学科的(multidisciplinary)协作不同,多学科协作通常意味着来自不同科学领域的人员聚集在一起协作,研究一个或多个共同的问题,目的是达成共识(Van den Besselaar & Heimeriks, 2001)。综合性跨学科研究需要更深入,而不仅仅是从不同角度对某种现象说些什么(Ros & Oberbichler, 2020)。这种方式可能是非常有益的,因为如果能够确定一致的目标,各领域之间可以相互推动进展。它还包括理解每个领域是如何工作是及其解决问题的方法(Gooding, 2020)。综合性跨学科工作在确立各学科彼此边界的同时,也应该为其架起桥梁。
在本文中,我们使用“工作流程”的概念来讨论综合性跨学科合作。我们认为,跨学科团队可以从理解所涉的每个学科的工作流程和传统中获益,并对各学科典型工作流程观点以示意图进行了综合,突出其相似点和差异。综合性路径是充分利用数字化资源的潜力所需要的。因此,我们详细阐述了所有领域结合在一起的研究步骤和任务,并最终提出了数字文化遗产研究工作的综合性数字解释学工作流程。
2 研究动机与方法
”
本文的目的是对数字管护者、人文研究者和计算机科学家之间的综合性跨学科研究进行阐明,这是由他们的共同期待——在数据中发现意义——所驱动的。关于数字文化遗产的研究,已经有很多文章分别从(数字)人文学者、图书馆员或计算机科学家的角度进行了阐述。一些论文还汇集了至少两个相关学科的观点。例如,古丁(Gooding)、罗宾逊(Robinson)等人、张(Zhang)等人和安吉拉基(Angelaki)等人论述了图书馆、信息科学与数字/计算人文之间的关系,而比曼(Biemann)等人和克鲁姆(Crum)等人则讨论了计算机科学与数字人文之间的距离、隔阂。凯曼(Kemman)对“数字人文合作”进行了反思,认为这种合作似乎“偏向于人文学科,而不是平衡数字和人文学科”。凯曼还指出,他用定量方法(问卷调查)来调查合作,并不能深入了解不同学科研究人员之间的共同基础的发展情况。
通过将三个学科的研究人员聚集在一起,本文了提供了关于以上话题的深入见解,并就其共同的和各自的愿景与动机展开了更广泛的讨论。本文的作者在2018—2021年在“NewsEye”这一跨学科的国际项目中展开了合作(Doucet et al., 2020)。在该项目中,计算机科学家、数学家、史学家、语言学家和图书馆员共同致力于开发新的方法和工具,以便有效地探索和利用历史报纸。常规会议(在线和面对面)、联合研究和发表、广泛的工具测试环节以及内外部研讨会构成了沟通和发展共同点的基础。本文回顾了我们从合作和跨学科中获得的经验(合作性自我民族志,CAE)(Hernandez et al., 2017),并将这些思考提炼为一个综合性跨学科工作流程建议。这些见解基于文献及与我们进行的研究密切相关的经验。
3 位于(数字)人文、图书馆和
计算机科学交叉处的数字文化遗产
”
3.1 需求及动机
图书馆员、人文学者和计算机科学家从不同方面参与数字化报纸等数字文化遗产的工作。图书馆员和人文学者在收集、组织和保存数字资源方面有着共同的兴趣,而计算机科学家和人文学者在获取和发现信息、知识(的方法)方面也有着共同的兴趣。如图1所示,图书馆是数据的提供者,是高效的存档和访问服务的提供者,其目标是获得各类用户;而计算机科学家可以被描述为解决方案、算法和工具的生产者和鉴定者;最后,人文研究者是计算机科学家提供的技术解决方案和图书馆提供的数字化材料的使用者。在数字文化遗产处理工作中,所有领域都发现了新问题、提出了新的解决方案,从而推动其发展,它们之间相互影响。
考虑到共同的需求和动机,跨学科研究领域的发展——如数字/计算人文、图书馆、信息研究或数字管护,作为混合领域弥合了学科界限以及“理论与实践、技术实施和学术反思之间的传统障碍” (Flanders et al., 2007)——是一个合乎逻辑的结果。这些领域再次紧密交织在一起(图2)。
数字管护涉及数字文化遗产数据的保存、推广和访问,将数据迁移到新格式、链接数据或添加上下文信息(Poole, 2013; Sabharwal, 2015)。图书馆和信息研究侧重于将技术成果应用于图书馆运营和服务(Hayes, 1985)。数字/计算人文产生了新的方法论及路径(随着多语言、多媒介等新挑战的出现。Liu, 2020),同时批判性地反思了与数字技术相关的实践,从而参与了对数字解释学的富有成效的讨论——认为它是一门需要跨学科和新技能的“中间艺术”。
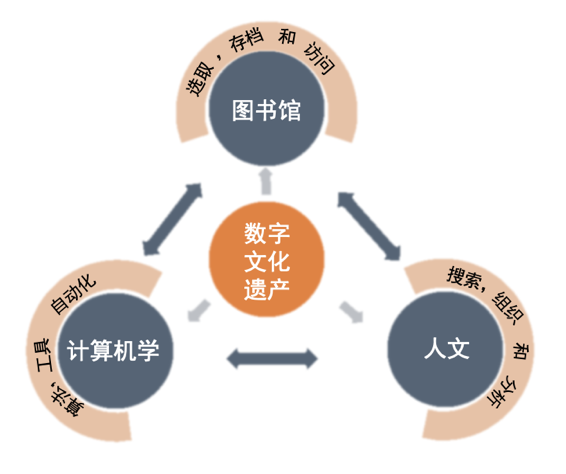
图1 处理数字文化遗产时计算机科学、图书馆学和人文学科各自的任务、兴趣和互动
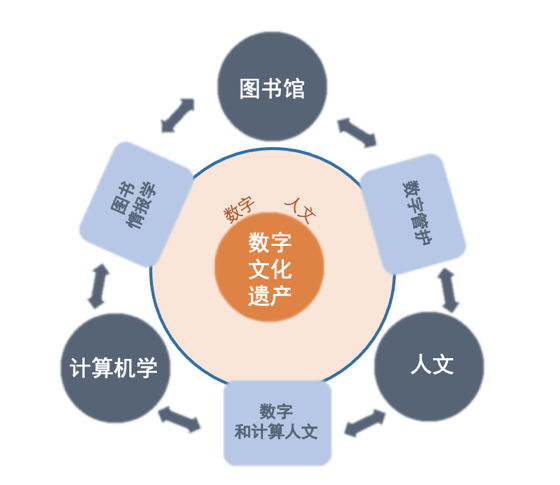
图2 处理数字文化遗产时的跨学科合作
3.2 异同点
学科之间存在着难以弥合的差异。对于参与项目的计算机科学家来说,突破方法开发上的限制是最有趣的;人文学科研究者则更倾向于将现有和传统的人文学科研究方法转移到数字世界中;对于图书馆员来说,比起那些对更广泛的用户群体最有用的东西,个人研究者的兴趣或项目有时是次要的。例如,对于一些人文学者来说,建立个性化的语料库以进行进一步的定性分析是一个重要的研究步骤,但对于计算机科学家来说却相当乏味,图书馆员也很少考虑这项工作。与此同时,人文学者有时发现,如果新开发的方法“仅仅”是定量的,或者超出了他们的“研究舒适区”,就很难将之整合到他们的研究中。
为了开展联合研究,并朝着更综合的方法发展,项目团队必须为应对挑战找到彼此的共同基础。尤其是在工具测试环节,很明显,人文学者常常发现图书馆或计算机科学家提供的功能僵化或笨重,有时对所需的数字解释学批判和对数字源、工具及方法的批判是不利的(这反过来又被认为对其他学科来说是不必要的)(Pfanzelter et al., 2021)。人文研究者,尤其是历史学者倾向于将数字计算方法仅仅视为传统辅助科学的现代化。对他们来说,能够控制对研究过程中运用传统原始资料(以及工具、方法、界面等)的每个步骤的评判,似乎至关重要,这也解释了为什么他们有时不愿意信任算法“发挥其魔力”(Korkeamäki & Kumpulainen, 2019)。
虽然不完全依赖计算工具是有道理的,但我们也了解到,这些论据有时被用来捍卫一种不必要的保守态度,即对大型数字语料库和计算方法提供的新机会嗤之以鼻。许多算法实际上对计算能力较强的人来说是透明的(例如,第4.3节),人文研究者已经相信许多算法的“魔力”,例如光学字符识别(OCR)、词性(POS)标记或命名实体识别(NER)。
计算机科学家对自己的领域也同样严格,他们倾向于从自己的角度分析和组织历史学者的任务和问题。科学家们有时会发现很难理解历史学者或图书馆员使用的概念、方法和其实际需求——当后二者的目标与计算机科学研究的目标和实践不一致时。而当一个有前景的新算法的原型实现需要历史学者付诸实践时,进一步的复杂情况变得清晰。计算机科学学术研究者有时不愿意满足额外工程工作(engineering work)的需求,即使这样能使得数字方法切实有用于人文学者。同样,我们也经历过人文学者有时不愿意从事繁琐的人工标注,而这项工作可用于评估计算机科学方法以及更重要的训练机器学习模型。
图书馆也有自己的实践和指导工作的标准。如果不正确理解和处理这些问题,可能会对合作的成效产生负面影响。例如,20世纪60年代首次开发的机器可读编目(MARC)标准,尽管在现代计算环境中其局限性广为人知,但仍在图书馆中被普遍使用(Park & Kipp, 2019; Tennant, 2004)。此外,图书馆对数字化对象的选择标准(以及用户可访问的内容)往往不符合用户和研究人员的兴趣;对特定时期和报纸话题的选择以及不完整的数字化过程影响了数字化报纸的面貌,有时还歪曲了时序上的代表性(Hauswedell et al., 2020)。最后,文化遗产的数字化改造无疑也是政治性的(Thylstrup, 2019),需要平衡相互竞争的要求和需求,如版权和技术可行性方面(IFLA, 2002)。
3.3 工作流程导向的跨学科合作
不同的工作流程,尤其是对其中步骤的不同理解,是难以找到共同基础的主要原因。尽管所有学科都有一个共同的目标,即理解和开发应用于数字报纸集合的创新方案和识别新问题,但它们都有各自不同的研究问题、目标以及计算方法的应用领域(见图3)。
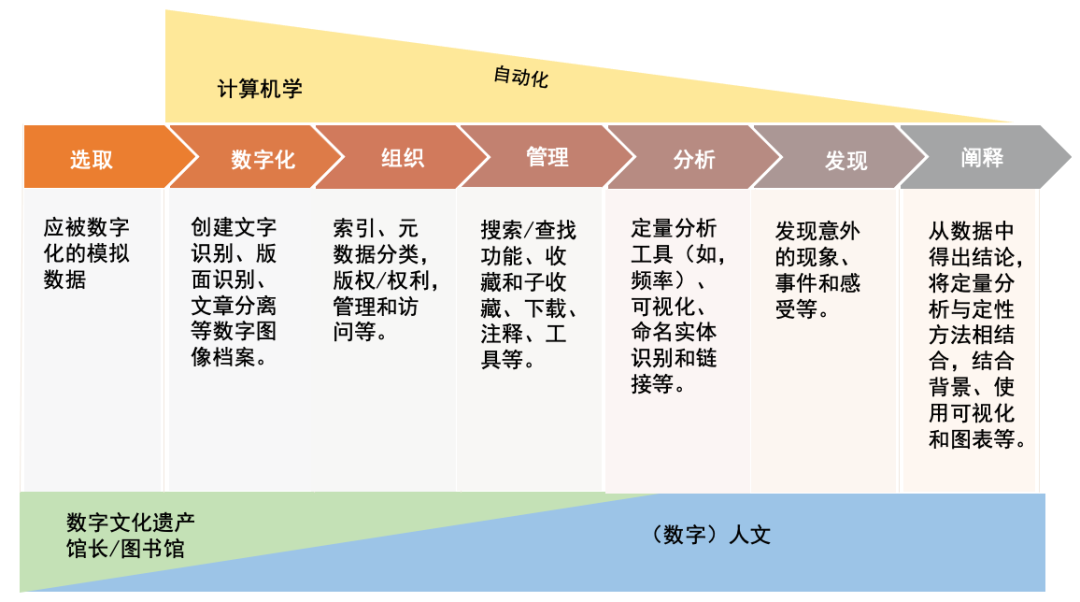
图3 各学科的参与情况及其(自动)计算方法的应用领域
并非所有应用数字方法、工具和算法的领域都涉及这三个学科,但它们有不同的需求和优先事项。此外,对于如何将数字方法应用于数字文化遗产,每个领域都有不同的传统和想法。
虽然文化遗产材料的数字化、结构化和管理是所有学科共享的步骤,但对于数字图书馆来说,数字化伴随着一个关于伦理考量的评估过程。例如,如果索引仅仅基于一项原始资料的文本内容,可能会因缺乏上下文而受损,并使用户难以搜索到。不同于计算机科学家,对于图书馆来说,提供上下文——比如以元数据的形式——不仅是一项技术任务,也是一项智力和劳动密集型任务。
而对于计算机科学家来说,数字方法在历史研究中的参与已经产生了一种结构化的子任务流水线视图,它以数字化开始,以解释结束。软件工具通常以一次处理一个或多个任务为目标,从而产生了若干步骤不同的工作流程。这不仅是技术上的意外或不便,更是计算机科学路径的反映:复杂的过程和问题被分割并组织成更小的过程和问题,以使得它们中每一个都能被尽可能独立地分析、解决和实施。子任务之间最少的交互和清晰的界面有助于对问题和软件的复杂性进行管理。不幸的是,对子任务进行硬性切分并将它们之间的交互最小化并不能很好地反映人文研究者的需求和研究过程。
再次回到人文研究者。他们对涉及数据组织、管理和分析的任务更感兴趣,他们对数字化材料和数据高度个性化的访问需求很难与标准化的工作流程或流水线相融。他们的目标是在数据中发现新奇的东西,并以创造性的方式解释他们的发现。他们倾向于将定量和定性的方法结合起来(如:Berg, 2020)——在数据、元数据和定性分析之间来回切换(Oberbichler, 2020b),以及结合所有研究步骤得出结论。与此同时,定性分析在计算机科学家和图书馆提供的技术基础设施中只起到了极小的作用。这是因为后面的任务很难实现自动化。虽然自动化是计算机科学家工作方式的核心,但随着流程中每一步的推进,挑战似乎变得越来越艰巨,也越来越容易出错。例如,如果图3中的“数字化”“组织”和“管理”任务的成功率为80%,那么简单地说,经过三个步骤后,错误率累积起来,最终的成功率为51.2%。这意味着,随着通过计算手段获得的支持越来越少,历史学者的作用将越来越大。
文化遗产机构正日益意识到用户群体和受众的不同期望。图书馆中的数字实验室正在成为一个研究领域,旨在帮助不同类型的用户尝试使用数字内容,“通过竞争、奖励、项目、展览和其他参与方式” (Chambers et al., 2019)。这些实验室,以及使用图书馆环境之外的既有工具,可以帮助解决用户对文本挖掘方法(Ehrmann et al., 2019)不断提高的期望,而不会使图书馆内档案材料的使用复杂化。这里的挑战仍然是,与图书馆的庞大数字馆藏相比,在研究项目中开发的工具通常使用小型数据集进行测试。这一问题对NewsEye团队来说也同样存在。例如,2017年的国际文件分析与识别会议(ICDAR)竞赛中使用的数据集约有2000页(Chiron et al., 2017),2019年约有15221页(Rigaud et al., 2019);相比之下,目前芬兰国家图书馆的数字化报纸集合包含1100多万页,奥地利报纸在线集合“ANNO”包含2300多万页。在NewsEye项目中,数据集由150万个报纸页面组成,这只是参与该项目的图书馆数字化馆藏的一小部分,但它应该足以为项目中使用和开发的工具提供可扩展性方面的经验。
3.4 创建综合性跨学科工作流程
为了打造一个成功的合作与沟通的过程,需要考虑学科之间的差异和共通之处。融合应用、任务和传统,包括混合方法路径及增加学科间的互动,已被确定为一个可能的共同目标(Mäkelä et al., 2019)。基于上述经验,我们认为这涉及对妥协的开放性:(数字)人文研究者需要对分析性和过程导向的思维持开放态度,将计算和数字化过程带来的可能性和局限性考虑在内;计算机科学家需要对人文学科的解释学传统持开放态度,并更深入地参与人文研究的解释和语境化过程;图书馆需要对外部参与保持开放,它们可以为协作提供空间,在对馆藏进行数字化时参与跨学科项目,并帮助资助实验。
数字解释学为创建一个综合性工作流程提供了一个潜在的框架,这些关注点可以在其中付诸实践(图4)。根据约翰·古斯塔夫·德罗森(Johann Gustav Droysen)的历史方法,历史知识通过三个研究步骤获得:启发,(来源)批判,解释。由于许多方法论的重申和解释学转向,三个研究步骤也与数字环境相关。对于历史学者来说,“启发”被认为是研究人员详细阐述其研究问题并发现、选择和收集(一手)材料的步骤(图4左部)。在第二步中,他们批判性地介入所选材料,提出相关性、真实性、适当性、重要性等方面的问题(图4中部)。第三步是解释材料,通过巧妙地结合信息和数据获得知识(图4右部)。
图4的综合性解释学工作流程在三个主要方面与流水线模型(图3)不同。首先,它强调数据(源材料、数据、子集合)的作用。其次,为了逐步获得更深入的洞见(发现、理解并探索数据,推导意义),它强调了对数据进行反复(定性)分析的重要性。第三,它强调以解释学的精神对数据和工具进行批判性反思,这需要方法和工具的开放性和透明度。相较于流水线模型以计算观点为主导,以上这些选择反映了人文研究者的观点。
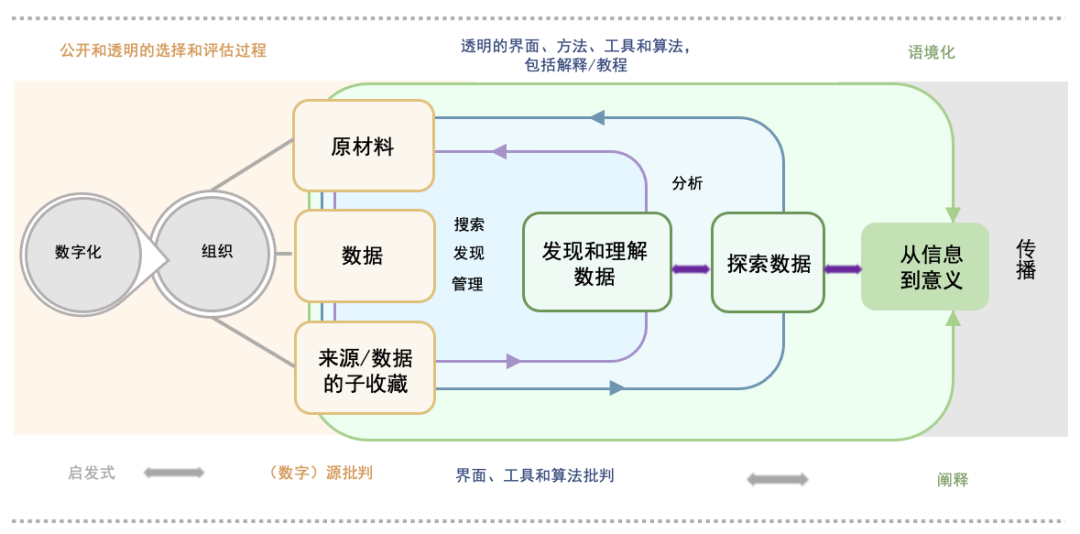
图4 跨学科数字解释学工作流程
工作流程的第一步(图4左部)基本上与图3相同。作为文化遗产的管护者,图书馆应该意识到为什么以及如何选择材料用以进行数字化的重要性,并且必须追踪这些过程的每一步。描述物理或电子资源的元数据信息共享在这一背景下也至关重要(Riley, 2017)。
综合性工作流程的中间和右边部分对计算机科学家提出了额外的挑战。需要开放透明的选择和评估过程,以及透明的界面、方法、工具和算法,来支持人文学者在检索、发现、管理和分析数字文化遗产材料的过程中进行批判性反思,并对工具和算法提出批评。分析、探索、解释和语境化步骤的交互和重复,意味着它们之间更紧密的整合,使得系统和界面设计越来越具有挑战性。
这里提出的跨学科数字解释学工作流程是一个概念,而不是一个实际的架构。它以一个简单的模型总结了我们在跨学科研究方面的经验和见解。不过,它是在NewsEye项目结束时开发的,理想情况下,这样的工作流程应该在跨学科项目开始时设计。我们相信,图4中的模型可以成为未来历史报纸研究项目中规划跨学科合作时的有用起点。
4 实践中的跨学科数字解释学:
三个例子
”
下面的章节展示了综合数字解释学工作流程如何支持对数字化源材料的批判性参与。为了简单起见,一方面,我们把重点放在启发式、(源)批评和解释等高层次的工作流程步骤上,另一方面,举例说明可以在工作流程中用于来源准备、组织、管理和分析的技术改进、新工具和方法。
4.1 数字化(光学字符识别和布局分析)
来源准备——含所有数字化步骤(包括版面分析和文本分割),是为报纸等文化遗产材料提供数字访问的第一步。内在过程在技术上并不是中立的,会受到亚政治过程的影响,首先即发生在为数字化做选择时(Thylstrup, 2019),因此它们是综合解释学工作流程的一部分(图4),这也意味着选择和评估过程应该对用户透明。
从技术角度来看,通过光学字符识别(OCR)或手写十字符识别(HTR)将历史文件的图像自动转换为电子文本是该工作流程中的第一个自动化步骤。版面分析和“文本分割”将经OCR识别的文本划分为“新闻单元”(news-units),是这一过程的第二个重要步骤。一些大型语料库早已完成数字化,但研究人员在使用数字化历史资料时面临的主要挑战之一是OCR系统自动提取的文本质量差(Boros, Linhares Pontes, et al., 2020; Huynh et al., 2020; Miller et al., 2000; Mutuvi et al., 2018; Nguyen, Boros, et al., 2020)。这个众所周知的问题影响着研究的全过程。国家和地区图书馆提供的数字报纸集合也不例外。由于原始纸质版本的质量有限,软件或工具也不合乎需要,2017年之前(甚至更晚)启动的数字化其OCR质量通常不令人满意,数字化过程有时几乎没有透明度可言。
随着时间的推移,人们对于元数据的重要性的认识才逐渐加深。这涉及模拟的材料,例如纸质版本的状态、出版频率、数字藏品的完整性、政治方向、变化中的编辑部门、语言等;也涉及数字化过程,例如所使用的软件和硬件、图像分辨率、文本识别准确度、可用性、所有权等。没有这些信息,数字源(以及工具、方法、界面等)批判就很难进行,数据集的可靠性也会降低。类似OCR(或HTR)的整体质量等OCR议题和数字化过程的透明度提升,有助于研究人员更好地评估OCR问题的影响,以便进一步研究。
但OCR不充分、数据集不完整或版面分割不令人满意,不一定是不可改变的事实。如果文本识别质量不令人满意,选择之一就是对数字化文档再次进行OCR (Kettunen et al., 2019; Neudecker et al., 2019)。Transkribus是一个识别和转录历史文献的综合平台,广泛用于这项任务。例如,在NewsEye项目中,因斯布鲁克大学(University of Innsbruck)和罗斯托克大学(University of Rostock)的团队伙伴用Transkribus对参与项目的奥地利、法国和芬兰的国家图书馆约150万页的数据集进行了再识别。这一过程带来了惊人的改进,输出的字符错误率低于1%。
由于计算成本,更重要的是由于早期数字化活动导致的低图像分辨率,对于非常大的数据集来说,再次进行OCR并不总是现实的。如果不进行“再OCR”,提高文本质量的另一种方法是使用OCR后期校正,NewsEye的研究人员已经对此做了详尽的研究(Nguyen et al., 2019):依赖深度学习、OCR错误分析以及公共基准(Chiron et al., 2017; Rigaud et al., 2019)。此外,拉罗谢尔大学(University of La Rochelle)和赫尔辛基大学(University of Helsinki)的计算机科学家正在研究能够消除残余OCR错误(也称为OCR噪声)的自动化工具和方法,如通过应用不同的拼写校正方法,或使用先进的神经网络算法连同单词表示方法(Hämäläinen & Hengchen, 2019; Huynh et al., 2020)。
在NewsEye项目中,“再OCR”文本被上传到NewsEye平台,这是一个实验性的、用于数字化报纸的原型界面。OCR提升后,很快就发现错误的自动版面分析和文本分割是创建子集的一个困扰。后者被认为对于从事定性分析、精读和泛读,以及希望能够导出整个文章集以做进一步分析的研究人员尤为重要。对于希望将(经可靠识别)切割出来的文章作为输入的自动文本分析方法来说,这同样是个问题。
4.2 检索、组织和管理
对于许多历史学者来说,找到特定的文章以及创建子集对他们的研究至关重要(Pfanzelter et al., 2021)。因此,研究人员需要能够检索、分类和组织数字化的可用的历史资源,并根据自己的需要调整数据集——于是建立了图4跨学科解释学工作流程的中间部分。检索文章或创建子库的任务,可以包括从识别有形实体关键词(如人、地点、事件)到识别更抽象、多样和微妙的概念(如主题、话题等),这些可以促进更深入的研究,如发现文化转变的模式、不同历史时期性别偏见的变化、新兴技术趋势,或者向新政治理念的过渡。
如普芬泽尔特(Pfanzelter)等人所述,案例研究表明,在查找与回答与个别研究问题相关的文章时,关键词仍然至关重要。同时,许多数字报纸界面的关键词检索中存在一些缺陷,比如替代性拼写、多义、缩写、改变词语用法、习语、拼写错误或遗漏(Bair & Carlson, 2008)。此外,许多检索要求很难在概念上定义,而且很难(如果不是不可能的话)仅通过单个关键字进行查找;以及在使用关键字查询构建特定主题的语料库时,总要在这样的检索的精度和召回率之间做出妥协(Chowdhury, 2010; Gabrielatos, 2007)。因此,在查找和理解数据的过程中,改进关键字搜索和关键字批判的方法非常重要。
大多数大型数字化报纸档案的界面都允许使用一系列检索选项(布尔运算符、通配符、短语搜索等)进行关键字高级检索,但不支持查找新的相关关键词(与所查询关键词类似的词),也不允许跟踪不断变化的单词用法或拼写错误。来自拉罗谢尔大学和赫尔辛基大学的NewsEye团队伙伴正在开发工具,在单词表示方法的帮助下支持更精细的关键字检索。单词的表示或嵌入是基于词汇的分布。它们是在使用大量文本集合的基础上创建的,可侦测出语义或句法上与给定单词相似的词。这些建议可以帮助用户找到在相似语境中使用的单词,以及识别出替代性的拼写。对于数据提供者来说重要的是,需要注意这些建议还提示了频繁发生的OCR错误(更多参考,详见Wevers & Koolen, 2020)。
为了满足创建个人数据集的需要,像“过去的媒体监控”(Media Monitoring of the Past)或NewsEye平台这样的界面提供了更精细的关键词检索。日期、地点、人名、组织或事件可能会让历史学者很感兴趣(Blanke et al., 2020; Sprugnoli, 2018)。在NewsEye中,这些关键词通过多语言命名实体识别(Boros, Hamdi, et al., 2020)、链接(Boros, Linhares Pontes, et al., 2020)及事件检测来辨识(Nguyen, Boros, et al., 2020)。目前的研究也在使用这种方法来链接多语言集合中跨语言的相关文档(Zosa, Granroth-Wilding, et al., 2020)。
自然语言处理方法可以进一步支持分类,例如过将关键词的上下文(出现关键字的文章)纳入考虑,对集合中的相关和非相关文章进行分类。我们的实验表明,通过统计学方法——如LDA主题建模和JS散度(Jensen-Shannon)中的距离度量,可以实现对集合的自动分组(Oberbichler, 2020c)。
然而,对数字报纸集合的预处理和预加工需要做相当多的工作,并要求有进行文本挖掘实验的意愿。为了在这些工作中支持更大的用户群,类似YouTube教程或现成的Jupyter笔记对于跨学科的数字解释学工作流程来说,是非常有帮助,也是必不可少的,因为它们是透明的,允许解释,并且可以协同开发。现在已经有很多项目,比如GLAM Workbench、BVMC实验室或NewsEye笔记本(notebooks),通过笔记本提供代码,用于不同类型的数据源和不同的方法。
4.3 语言使用模式分析
许多历史学者将报纸中的语言数据作为研究报道所反映的历史过程的切入点,但也有不少历史学者对话语本身感兴趣,这意味着人们对语言作为历史变化的指标的兴趣正在重新升温。这类研究从使用界面和算法方法来寻找相关来源,转向使用它们来生成对过去话语变化的表述。例如,一个主题模型可以用来对相似的文档进行聚类,并生成一个子类别用于更深入研究,但它也可以用作数据中某个研究对象的指标。按照Pääkkönen & Ylikoski (2020)的说法,前者可以被称为主题工具主义,而后者是主题现实主义的一种形式。这种区分也适用于对大规模文本数据集进行量化的一般方法。
对于语言使用模式,可以通过非常简单的方法来研究,或使用复杂的计算方法进行分析。最简单的途径包括分析词频(Church & Hanks, 1989),更复杂的研究则采用基于关键度(keyness)、词频—逆文本频率(TF-IDF)的语料库语言学方法,或计算上更复杂的方法,如主题模型(Wallach, 2006)、词嵌入(Mikolov et al., 2013)。数字报纸集合研究的方式极大地影响了研究人员可以如何估算模式。有了全文的数据转储(有关将数字馆藏创建为数据集的方法,请参见Candela et al.,2020),定量分析和将频率相关问题进行可视化的可能性几乎是无穷无尽的,但这需要数据处理技能、领域专业知识和计算机科学知识(Ehrmann et al., 2019; Pfanzelter et al., 2021)。不过,为特定报纸数据集定制的界面通常为研究人员测算语言使用模式提供了一些可能性。然而,频率变化的原因各不相同,要理解它们,往往需要从不同角度探索频率。
频率分析在方法上对计算机科学家不具挑战性,但人文领域的专家却很难掌握,从这点来说,它常常处在夹缝当中。图形用户界面中提供的工具通常缺少对不同基线的频率进行标准化的可能性。例如,比较两份报纸上带有政治色彩的词出现的次数并不具有很大的信息量,除非我们能够根据两份报纸总共发布的标记或其他相关基线对它们进行标准化。只有这样,我们才能获得可比较的解释结果(见Jenset&McGillivray,2017,第1至35页)。设定一个切合的基线可能不是一项简单的任务,因为标准化的结果最终可能会反映出与最初意图不同的东西(例如,反映了编辑兴趣而不是词语偏好的差异)。因此,一个综合的解释学工作流程需要领域专家(界定什么是相关的、什么是已知的)和计算机科学家(界定什么是可以计算的、什么样的元数据是可用的)两方的专业知识;而在分析和解释数据的过程中,对频率和文本挖掘工具以及历史实践本身的批判性反思至关重要。
如果不针对具体的人文研究问题进行调整,就无法使用更精细的方法来分析历史变化。这就需要超越界面,无论其是否已经置入复杂的工具,并且要求在专业人文研究者和计算机科学研究者之间展开合作(Van Gorp et al., 2019)。例如,词嵌入可用于给出新的关键词建议进行探索,也可用于追踪意义随时间所发生的变化,即回答思想史或历史语义学中传统上与定性研究相关的问题(Friedrich & Biemann, 2016; Wevers & Koolen, 2020)。然而,使用这些方法需要了解所使用的参数(如词类的频率阈值)、选择聚类方法(如k-means聚类、AP聚类),或简单评估对于一般词类不同算法(如Word2Vec、Scot)的反应。诸如此类的选择不仅是计算方面的问题,对人文解释也有影响(Marjanen, Kurunmäki, et al., 2020)。
与词嵌入相比,使用主题模型来表现语言使用模式的历史变化更加困难,因为模型产生的主题与数据中记录的语言使用之间的直接联系更弱(Marjanen, Zosa, et al., 2020)。不过,如果我们想了解数据的总体情况以及数据中捕捉到的话语景观的变化,主题模型目前仍然是最有效的。然而,不同的方法[如时间切片LDA或动态主题建模(DTM)]如何表现历史变化是一个开放性的问题。对这些表现的质量进行评估是困难的,因为话语中无法产生关于历史变化的客观基本事实,但为了支持人文解释,评估仍然是需要的。这同样需要人文科学和计算机科学之间的对话。
5 讨论
”
即使所有参与者都有良好的意愿,跨学科协作也可能很困难。在NewsEye项目中,来自各个学科的研究人员因对数字历史报纸的共同兴趣及参与合作研究和方法开发的意愿而走到一起。虽然共同的兴趣和目标占据主导,但未满足的期望或失败的合作也会导致研究者们偶尔撤回到自己的学科领域。为了克服这些分歧,团队需要开始思考问题的根源,进而思考可能的解决方案。上一节中的三个例子突出了其中的一些方面。
我们为项目发展出了一个工作流程视角,并最终形成了一个数字解释学工作流程,作为对历史报纸进行综合性跨学科研究的模型。虽然很明显,单一的模型不能完全涵盖计算机科学家、人文学者和图书馆员的需求和工作流程,但我们相信,工作流程的视角可以帮助整合数字解释学中的数字界面、工具、方法和算法,正如上述三个例子所展示的。本文提出的多部分、跨学科的工作流程旨在作为示例和参考点。
为了实现综合性数字解释学,我们认识到以下几点的重要性:(1)把握多学科和跨学科研究之间的差异;(2)理解每个学科的动机、习惯和对彼此的期望;(3)接受每个学科都需要加紧努力,以使其他学科能够进行实际研究这一点。我们将简要讨论工作流程视角如何有助于实现以上要点。
首先,为自己的项目设计一个工作流程,或者对本文提出的工作流程进行调整,迫使研究人员明确考虑他们希望实现多大程度的整合和跨学科,或者他们的项目是否更多地属于多学科合作。
第二,学科之间的相互理解是从交流中产生的。反思和讨论工作流程,是找到对彼此观点、习惯和传统的共同看法的第一步。就每个学科的期望和局限进行沟通似乎至关重要,因为对它们的不言明的假设往往是错误的。这需要投入时间和精力去理解每一个学科。
第三,一个详细的工作流程——比这里介绍的更详细——可使必要的任务和组件更加明确。这有助于确定每个学科的实际边界并在它们之间进行协商,例如,就各方应该为虽在自己利益兴趣之外、但在专长之内的重要任务做出贡献这一点达成一致。
以NewsEye项目中的一个观察为例。出乎计算机科学研究人员的意料,(数字)人文学者迫切需要能够定义子集以便保存和导出,因为这些子集为他们提供了更好的机会,可以进行定量大数据评估之外的研究。虽然对计算机科学研究人员来说,这似乎是一个在理论上微不足道的事情,但它现在是NewsEye平台最常用的功能之一。当涉及任何一方都不认为是研究的任务时,协商妥协也很重要。例如,需要计算机科学研究人员执行的软件工程或者需要(数字)人文学者执行的人工标注,尽管这两项任务对于每个领域的进展都是必要的。我们认为,在跨入任何跨学科的学术合作时,意识到并明确界定对不同任务的期望和承诺水平是至关重要的。
6 结论
”
在NewsEye项目中,我们认识到有三个方面阻碍了对历史报纸进行成功的跨学科研究:(1)在开发/使用数字工具时存在不同的动机、目标、需求和假设;(2)对学科之间的差异缺乏了解;(3)有些任务是合作研究所需的,但对任何一方都没有科学上的意义。
基于文献和我们在NewsEye项目中的经验,我们建议工作流程导向的视角可以帮助避免一些问题。工作流程是相关学者讨论各种概念、过程和实践的便利工具。它们可以帮助明确不言明的假设(上文第1点),增加学科之间的理解(第2点),还可以识别和驱动那些否则会被忽略的任务(第3点)。
我们提出了一个更具体的综合性解释学工作流程,它融合了过程导向的路径和数字解释学意义上的批判性反思。在这个工作流程中,我们强调分析、探索、解释和语境化步骤之间的密切互动,强调定性研究步骤在整个工作流程中的重要性,还强调批判性反思是工作流程的一个重要组成部分——从数字化和组织开始,以传播为结束。
我们给出了三个数字解释学的实际例子,解释用户界面和工具如何支持在启发、(来源)批判和解释中进行批判性反思。我们介绍了数字报纸研究的新方法和发展,表明成功的跨学科合作和研究需要的不仅仅是共同的愿景和目标,还需要找到共同的路径方法——能同等地支持推进历史研究问题、创建透明的数字方法以及对分析和搜索结果进行解释。
本文提出的综合性数字解释学工作流程既可以作为对历史报纸研究进行结构化的模型,也可以作为规划跨学科研究时讨论期望和承诺的概念工具。
校对 | 刘为之
排版 | 郭静怡
 学术活动
学术活动